Porque é que os chips e o HBM se tornaram os hotspots iniciais
Ao analisar a atual vaga de IA, os setores que primeiro atraíram uma avaliação concentrada nos mercados de capitais centraram-se quase todos nos chips e na memória. O raciocínio é simples: a rápida iteração de modelos de grande escala depende de capacidades de treino em larga escala, e o constrangimento mais direto à capacidade de treino é a oferta de poder computacional de topo. Quanto mais GPU for possível adquirir, maior será a oportunidade para treinar modelos maiores, fornecer serviços cloud mais robustos e construir fossos de ecossistema mais profundos.
À medida que o poder computacional de cada chip aumenta, surgem rapidamente novos estrangulamentos. Os sistemas de IA não precisam apenas de "calcular rápido", mas também de serem "alimentados suficientemente". Isto elevou rapidamente a importância estratégica da memória de banda larga elevada (HBM). Para o treino de modelos de grande escala e inferência de elevada densidade, a largura de banda da memória deixou de ser uma preocupação secundária — é agora uma variável central que impacta diretamente o throughput, a latência e a eficiência energética.
Relatórios públicos recentes reforçam ainda mais esta lógica. Segundo meios como a Reuters, a gestão do SK Group referiu que as carências globais de wafers podem persistir até 2030, e a SK Hynix indicou que a procura por HBM deverá superar a oferta durante vários anos. Isto demonstra que o foco do mercado nos chips e no HBM não é apenas motivado por sentimento; a IA está a reestruturar fundamentalmente a dinâmica de oferta e procura de semicondutores de topo.
Existem três razões principais para os chips e o HBM se terem tornado os hotspots iniciais:
-
O estrangulamento é mais evidente: Durante a fase de treino, a diferença de poder computacional é mais fácil de quantificar e mais reconhecível pela indústria e pelos mercados de capitais.
-
A expansão da oferta é a mais lenta: Lógica de topo, embalamento avançado e HBM são todos segmentos de barreira elevada, com ciclos de expansão longos, requisitos de certificação rigorosos e desafios significativos de substituição.
-
A transmissão de preços é a mais direta: Quando as carências de oferta persistem, as variações nas encomendas, preços e lucros refletem-se mais facilmente no desempenho das empresas.
Assim, chips, HBM e embalamento avançado continuaram a aquecer nos períodos recentes, em alinhamento com os fundamentos da indústria e as preferências do mercado.
Porque é que a infraestrutura de IA está a mudar do treino para a inferência
Embora chips e HBM permaneçam críticos, o centro de gravidade da infraestrutura de IA já começou a deslocar-se. Antes, o foco da indústria era sobretudo o treino de modelos; agora, mais recursos estão a ser direcionados para o deployment de inferência e operações de produção.
O motivo é claro: o treino define o limite superior da capacidade do modelo, enquanto a inferência determina a escala da comercialização. O treino é uma atividade de elevado investimento, envolvendo apenas algumas empresas líderes, enquanto a inferência ocorre em cada chamada real de utilizador. Cenários como pesquisa, produtividade de escritório, apoio ao cliente, publicidade, geração de código, geração de vídeo, base de conhecimento empresarial e automação de Agent dependem de pedidos de inferência contínuos.
Segundo o Relatório de Estratégia de Aplicação Empresarial 2026 da F5, 78% das empresas já executam inferência de IA como capacidade operacional central, e 77% acreditam que a inferência — e não o treino — é o principal cenário de atividade da IA. Estes dados enviam um sinal forte: a IA está a sair do laboratório para sistemas de produção, e a procura está a passar da “competição de capacidade de modelos” para a “competição de eficiência operacional”.
Quando a IA entra nos processos reais das empresas, as preocupações principais passam do tamanho dos parâmetros do modelo para métricas operacionais como:
- A latência é estável?
- Os custos são controláveis?
- É possível encaminhar e alternar entre vários modelos?
- Os dados estão seguros?
- Os resultados são auditáveis?
- O sistema pode integrar-se com plataformas empresariais existentes?
Isto significa que a infraestrutura de IA está a evoluir de clusters de treino únicos para sistemas de operação de inferência mais complexos, incluindo:
- Plataformas de serviço de modelos
- Estruturas de aceleração de inferência
- Agendamento e encaminhamento multi-modelo
- Recuperação vetorial e gestão de contexto
- Sistemas de orquestração de Agent
- Auditoria de segurança e controlo de acesso
Esta mudança também é visível nas estratégias dos fornecedores de hardware. Na sua libertação pública de 2026, a Google Cloud enfatizou ainda mais os produtos TPU otimizados para inferência, destacando baixa latência, contexto longo e elevada concorrência de Agent. A própria arquitetura de hardware está a passar de “primeiro o treino” para “primeiro a inferência”.
Porque é que o verdadeiro estrangulamento se expandiu para data centers e energia
Se a principal preocupação na fase anterior era “Existem GPU disponíveis?”, a questão premente agora é “Depois de ter GPU, é possível implementá-las de forma fiável?”
Isto marca a segunda fase da infraestrutura de IA. As GPU continuam a ser ativos centrais, mas só quando combinadas com data centers, energia, sistemas de refrigeração, redes, switching e operações podem ser transformadas em verdadeira produtividade. Ou seja, o estrangulamento na indústria de IA deslocou-se do hardware individual para a capacidade total do sistema.
Vários desenvolvimentos públicos recentes destacam esta tendência:
- Empresas tecnológicas líderes na América do Norte vão continuar a aumentar os investimentos em IA em 2026, investindo não só em chips, mas também em campus de data centers, arquitetura de rede e expansão de infraestrutura.
- Previsões públicas do setor energético dos EUA mostram que o consumo de energia vai atingir novos máximos em 2026 e 2027, com os data centers e a IA como principais motores.
- Vários projetos de data centers de IA de escala hiper estão agora focados em centenas de megawatts de fornecimento de energia, arrendamentos de longo prazo e desenvolvimento de campus, indicando que o foco da indústria passou para “como suportar o poder computacional”.
Isto significa que a indústria de IA se está a tornar cada vez mais semelhante a um sistema de indústria pesada, e não apenas à expansão asset-light da era da internet. A variável chave para a expansão futura está a passar de “conseguimos desenhar chips mais fortes” para “conseguimos garantir rapidamente energia, terreno, refrigeração e recursos de rede”.
Do ponto de vista da indústria, esta transformação traz pelo menos quatro consequências:
-
Os data centers passam de ativos de TI a ativos estratégicos: workloads de IA de elevada densidade exigem novos padrões de instalações, distribuição de energia e refrigeração.
-
A energia torna-se o novo recurso escasso: Em algumas regiões, as GPU já não são o recurso mais difícil de obter — o acesso estável e de longo prazo à energia é ainda mais raro.
-
A importância da refrigeração e da refrigeração líquida está a aumentar rapidamente: À medida que a densidade de potência dos clusters de IA aumenta, os métodos tradicionais de refrigeração tornam-se insuficientes.
-
As interligações de alta velocidade determinam a eficiência dos clusters: À medida que o poder computacional escala, o desempenho do sistema depende menos das placas individuais e mais da arquitetura de rede e switching.
Assim, a competição central na infraestrutura de IA já não é sobre avanços pontuais, mas sobre colaboração ao nível do sistema.
As cinco direções de crescimento mais rápido nos próximos 2–3 anos
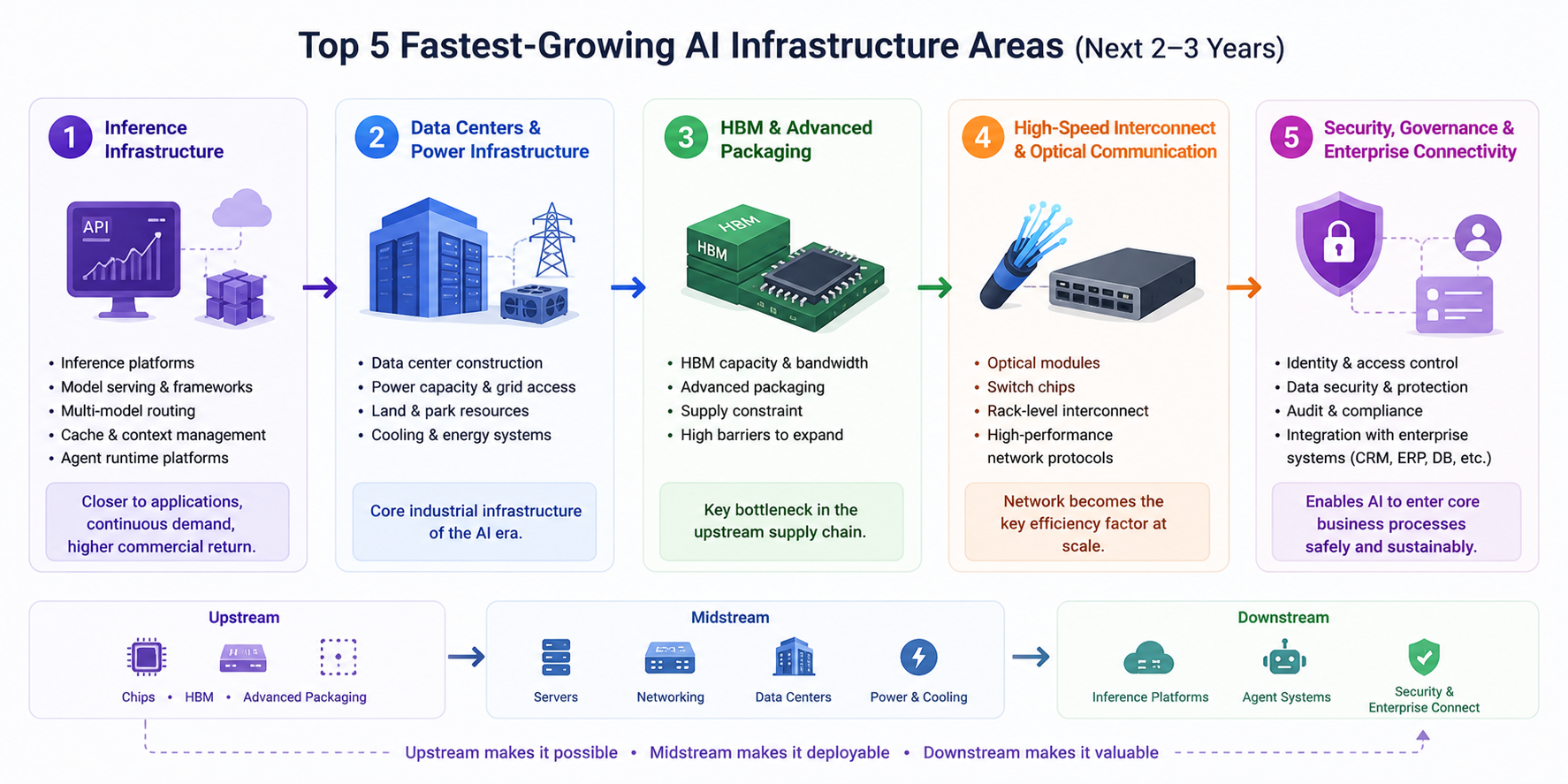
Com base em informações públicas recentes e mudanças na cadeia industrial, as direções de crescimento mais rápido para infraestrutura de IA nos próximos 2–3 anos podem ser resumidas em cinco categorias:
-
Infraestrutura de inferência: Esta é a que merece maior atenção contínua. À medida que as aplicações de IA entram rapidamente em produção, plataformas de inferência, estruturas de serviço de modelos, encaminhamento multi-modelo, caching e gestão de contexto, e plataformas de operação de Agent vão expandir-se rapidamente. Em comparação com o treino, a procura por inferência é mais distribuída, sustentada e próxima dos retornos comerciais.
-
Data centers e suporte energético: Os data centers estão a tornar-se a infraestrutura industrial central da era da IA. Quem conseguir garantir quotas de energia, terreno, condições de campus e sistemas de refrigeração mais rapidamente estará melhor posicionado para a próxima vaga de expansão do poder computacional. Nos próximos anos, a velocidade de construção de data centers vai influenciar profundamente o ritmo de crescimento da indústria de IA.
-
HBM e embalamento avançado: Este continua a ser um dos estrangulamentos mais críticos na cadeia de fornecimento upstream. À medida que o desempenho dos chips aumenta, também aumentam os requisitos de capacidade, largura de banda e tecnologia de embalamento do HBM, enquanto a capacidade relacionada é difícil de escalar rapidamente — o que significa que a elevada prosperidade deverá persistir.
-
Interligações de alta velocidade e comunicações ópticas: À medida que os clusters de IA escalam, as redes tornam-se a variável chave para a eficiência global. Módulos ópticos, chips de switching, interligações ao nível de rack e protocolos de rede mais eficientes vão tornar-se capacidades fundamentais para treino e inferência.
-
Governança de segurança e conectividade empresarial: Embora esta área seja menos proeminente a curto prazo do que chips, o seu valor a longo prazo é imenso. Quando a IA empresarial for integrada com CRM, ERP, bases de dados, repositórios de código e sistemas de conhecimento, controlo de acesso, auditoria, proteção de dados sensíveis, rastreio de resultados e governança de conformidade vão tornar-se essenciais. Esta camada determina se a IA pode realmente entrar nos processos empresariais nucleares.
O caminho de transmissão pode ser resumido numa linha principal mais clara:
- Upstream: chips, HBM, embalamento avançado
- Midstream: servidores, redes de switching, data centers, energia e refrigeração
- Downstream: plataformas de inferência, sistemas de Agent, governança de segurança e integração empresarial
O upstream determina “se pode ser construído”, o midstream determina “se pode ser implementado”, e o downstream determina “se pode ser utilizado e continuar a criar valor”.
Conclusão: a competição de IA entra na era da engenharia de sistemas
Nos últimos anos, o mercado perseguiu inicialmente chips e HBM porque estes setores eram os mais escassos e ofereciam a história de oferta e procura mais clara. Mas à medida que a IA passa de uma corrida de treino para deployment de inferência, a lógica da indústria mudou fundamentalmente. Daqui em diante, o verdadeiro determinante do crescimento não é apenas o desempenho de chips individuais, mas se toda a infraestrutura pode operar de forma coesa.
Uma estrutura mais organizada para compreender a fase atual da infraestrutura de IA é:
- O treino define o limite superior da capacidade
- A inferência determina a escala da comercialização
- Os data centers e a energia ditam a velocidade de expansão
- A governança de segurança determina a profundidade da adoção empresarial
Isto significa que a próxima vaga de oportunidades de infraestrutura de IA não se vai limitar aos chips, mas vai desenrolar-se em “infraestrutura de inferência + data centers + sistemas energéticos + interligações de alta velocidade + plataformas de governança empresarial”.
Numa perspetiva de longo prazo, a IA está a evoluir de uma indústria de competição de modelos para uma indústria de engenharia de sistemas. Quem conseguir criar sinergias entre poder computacional, redes, energia e plataformas operacionais estará melhor posicionado para liderar a expansão do setor nos próximos 2–3 anos.
Lembrete de risco: Este artigo não constitui aconselhamento de investimento e destina-se apenas a fins informativos. Investir com cautela.







