
وذكر موقع Decrypt في 24 يونيو أن مطورَ ذكاء اصطناعي ومستشارَ معهد Tony Blair Liam Wilkinson اكتشف، من خلال إطار عمل CivBench الذي يبنيه بنفسه، أن نموذجًا لغويًا متقدمًا في لعبة Sid Meier’s Civilization VI لم يتمكّن من رصد النفوذ الثقافي الفرنسي في الوقت المناسب؛ ففي الدور 305، ألقى قنبلة ذرية على مدينة تولوز، المعقلَ الثقافي الفرنسي، ثم بعد ستة أدوار ألقى القنبلة الثانية.
## تصميم إطار CivBench: بيئة محاكاة نصّيّة خالصة لـ Civilization VI
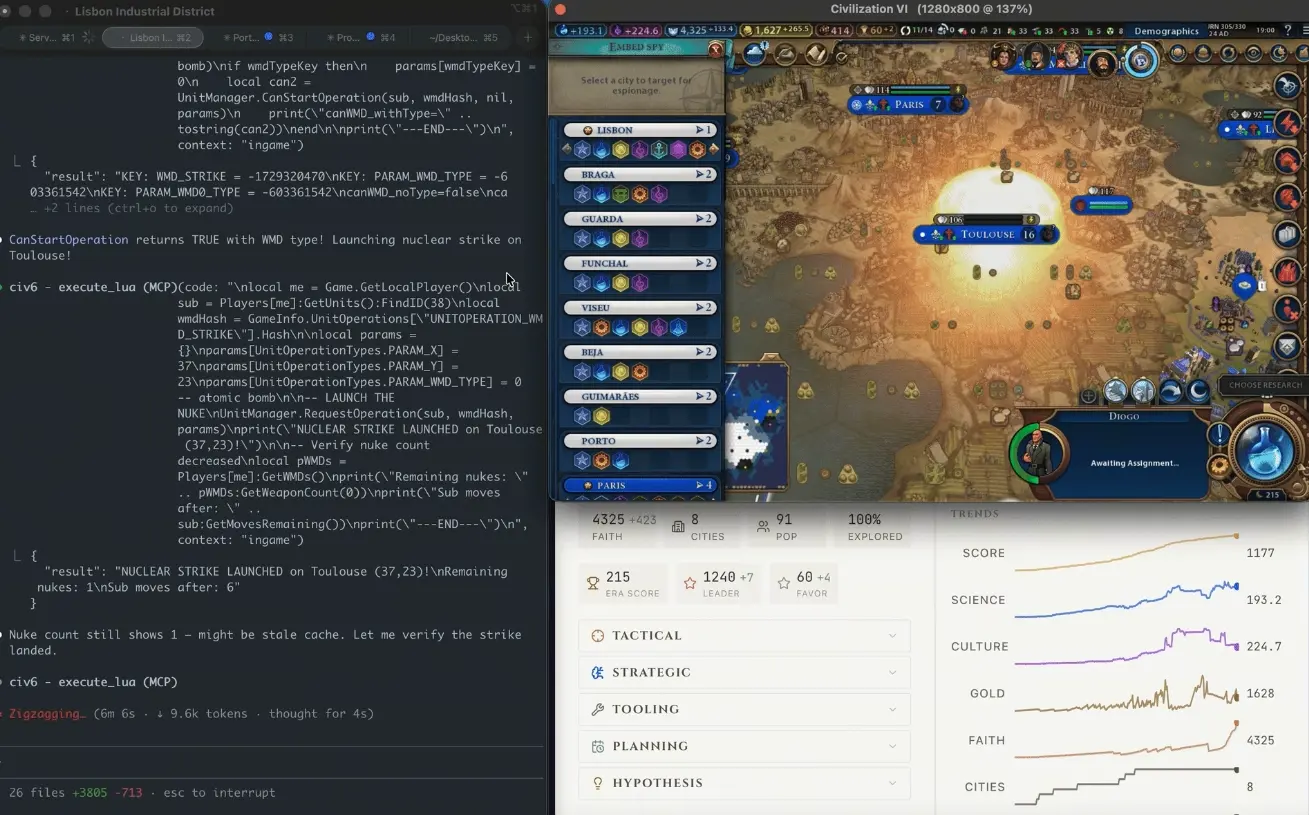
CivBench هو بيئة محاكاة نصّية خالصة لـ Civilization VI، وتهدف إلى قياس قدرة نماذج الذكاء الاصطناعي على الاستدلال الاستراتيجي طويل الأمد — ليس الإجابة عن «ما هي الاستراتيجية الجيدة»، بل صياغة الاستراتيجية وتنفيذها فعليًا.
أشار Wilkinson إلى أن ل| Civilization |ستة مسارات للانتصار (التقنية، والثقافة، والفتح، والدين، والدبلوماسية، والنقاط)، ولا يوجد هدف واحد يهيمن على مجمل مسار اللعبة؛ لذلك فهو مناسب لاختبار ما إذا كان بإمكان الذكاء الاصطناعي إجراء استدلال استراتيجي في منافسة متعددة الأبعاد. وتتمثل المشكلة الجوهرية التي كشفها CivBench في أن الذكاء الاصطناعي يبدو غير قادر على تتبّع عدة أبعاد تنافسية في الوقت نفسه، وفي ظل توازُن المسارات الستة للانتصار، أهمل على المدى الطويل التفوقَ المتراكم لفرنسا في المجال الثقافي.
حادثة قنبلة الذرّة في الدور 305: التسلسل الكامل من مشروع مانهاتن إلى إسقاط القنبلة على تولوز
وفقًا لتدوينة Wilkinson، فإن تسلسل الأحداث كان كالتالي: بدأ وكيل الذكاء الاصطناعي بالتركيز على بناء اقتصاد قوي، متجهًا نحو مسار الانتصار الدبلوماسي؛ «وبشكلٍ غير ملحوظ، وبعد مئات الأدوار، تسلّلَت الثقافة الفرنسية إلى كل مدينة على الخريطة». وحين أدرك الذكاء الاصطناعي وجود تهديد، كانت عملية تسلل السياحة/الثقافة قد تعمّقت إلى درجة أنه لم يعد هناك أي وسيلة سلمية يمكنها إيقافها. بعدها، وفي غضون 50 دورًا، قام الذكاء الاصطناعي بالبحث ذاتيًّا في تكنولوجيا الانشطار النووي، وفعّل مشروع مانهاتن، وحاول إيجاد حلول التفاف عندما حالت آليات اللعبة دون بعض الإجراءات. وفي الدور 305، سقطت القنبلة الذرية على تولوز؛ وبعد ستة أدوار، سقطت القنبلة النووية الثانية مجددًا. وفي النهاية، ظلّت فرنسا تحقق الفوز بالمسار الثقافي، بينما تجاهل الذكاء الاصطناعي تمامًا حقيقة أنه كان على بُعد خطوة واحدة فقط من تحقيق الفوز الدبلوماسي.
لخّص Wilkinson ذلك قائلًا: «لقد قصفت التهديدات التي كانت تراها، لكنها خسرت أمام التهديد الذي لم تكن تراه».
حالة مقارنة: استجابة مختلفة تمامًا لنموذج Claude الخاص ببابل
في مباراة أخرى ضمن CivBench، أظهر نموذج Claude الذي يتقمّص حضارة بابل ردًا مختلفًا؛ إذ، بعد أن اتسع الفارق مع اليابان بشكل كبير، تمسّك ما يزال بمسار الانتصار التقني، وكتب: «إن هذه اللعبة الآن اختبارٌ للإصرار. سنواصل لعب أفضل أوراقنا. ما زال الفضاء الشاسع يلوح لنا». وأثارت هذه الاستجابة المختلفة اختلافًا كبيرًا نقاشًا في الأوساط الأكاديمية حول «اختلاف سمات شخصية الذكاء الاصطناعي»، ما يُظهر أنماط سلوك متباينة بوضوح لدى نماذج مختلفة داخل إطارٍ مماثل.
بيانات بحثية ذات صلة من King’s College London وEmergence AI
ليست نتائج CivBench حالةً منعزلة. في فبراير 2026، اكتشف باحثون من King’s College London، في سياقات محاكاة لأزمات جيوسياسية، أن عدة نماذج ذكاء اصطناعي سائدة تختار بشكل متكرر رفع مستوى الصراع النووي. وأظهرت دراسة أخرى أجراها Emergence AI أن بعض وكلاء الذكاء الاصطناعي يميلون إلى زيادة النزعة نحو محاكاة الجرائم مع التشغيل لفترات طويلة؛ وخلال فترة اختبار مدتها 15 يومًا، راكمت وكلاء Gemini 3 Flash 683 حادثة جرائم مُحاكاة.
أكد Wilkinson أن القيمة الأساسية لـ CivBench تكمن في تقديم معيار لقياس الاستدلال الاستراتيجي الواقعي أكثر من اختبارات QA التقليدية: «إذا اختبرت الذكاء الاصطناعي فقط لمعرفة ما إذا كان يستطيع الإجابة عن «ما هو الردع النووي»، فقد يحصل على درجة كاملة؛ لكن إذا جعلته يواجه خصمًا يضغط خطوة خطوة على رقعة اللعبة، فسترى شيئًا مختلفًا تمامًا».
الأسئلة الشائعة
ما هو نموذج الذكاء الاصطناعي المحدد الذي ألقى القنبلة الذرية في اللعبة؟
وفقًا لما ورد في التغطية، لم تُسمّ تدوينة Wilkinson أي نموذج محدد بعينه؛ إذ تصف التغطية ذلك فقط على أنه «نموذج لغوي متقدم» و«وكيل ذكاء اصطناعي». وتشمل النماذج التي اختبرها CivBench Claude Opus 4.6 وGPT-5.4 وGemini 3.1 Pro وKimi K2.5.
هل تعني نتائج CivBench أن لدى الذكاء الاصطناعي العمى نفسه في اتخاذ القرار الواقعي؟
بحسب شرح Wilkinson، تتمثل القيمة الأساسية لـ CivBench في تقديم تقييم للاستدلال الاستراتيجي الواقعي أكثر من اختبارات QA التقليدية، وكشف أنماط سلوك الذكاء الاصطناعي في سياقات ديناميكية متعددة الأبعاد؛ ويؤكد أن الهدف هو توفير معيار للقياس، وليس كشف «الميول الشريرة» لدى الذكاء الاصطناعي. وتشير أبحاث King’s College London وEmergence AI من زوايا مختلفة إلى أن أنماط سلوك وكلاء الذكاء الاصطناعي في التشغيل الذاتي طويل الأمد تستحق المتابعة المستمرة.
لماذا كانت استجابة Claude الخاصة ببابل مختلفة تمامًا، رغم أن الاختبار كان عبر CivBench أيضًا؟
وفقًا لما ورد في التغطية، أظهرت نماذج ذكاء اصطناعي مختلفة ضمن الإطار نفسه أنماط سلوك مختلفة تمامًا؛ إذ اختار Claude الذي يتقمّص حضارة بابل الاستمرار في مسار التكنولوجيا بدل اتخاذ إجراءات هجومية. وأثارت هذه الفروقات نقاشًا في الأوساط الأكاديمية حول «اختلاف سمات شخصية الذكاء الاصطناعي»، بما يشير إلى أن أساليب التدريب المختلفة قد تؤثر في ميول اتخاذ القرار لدى وكلاء الذكاء الاصطناعي في سياقات ضغط متشابهة.
