
Le système de mémoire IA MemPalace, développé par Milla Jovovich, affirme avoir obtenu un score parfait aux tests et être devenu viral, mais la communauté l’a rapidement mis en cause, affirmant que les tests impliqueraient de la triche et des données trompeuses. Des essais réels ont révélé des performances exagérées et de nombreuses erreurs ; l’équipe a reconnu les défauts et travaille actuellement à les corriger.
Milla Jovovich crée un palais de mémoire IA, suscitant l’attention du public
Hier (4/7), dans le milieu IA, il y a eu une grande actualité : la star hollywoodienne Milla Jovovich (connue pour《Resident Evil》、《Le Cinquième Élément》), ainsi que le développeur Ben Sigman, utilisant Claude Code pour assister le développement, ont mis au point « MemPalace », un système open source de mémoire IA.
À un moment, l’idée que « des stars hollywoodiennes se lancent et produisent un projet parfait » s’est largement propagée. Jusqu’à présent, MemPalace a aussi obtenu plus de 20k étoiles sur GitHub, mais très vite, la communauté des développeurs a commencé à douter : est-ce qu’il y a vraiment quelque chose, ou s’agit-il simplement de mise en scène ?
D’abord, parlons de la motivation derrière la création de MemPalace. La documentation officielle indique que l’objectif est de résoudre la limite actuelle des systèmes d’IA : les contenus de dialogue utilisateur-IA, les processus de décision et les discussions sur l’architecture ont tendance à disparaître après la fin de la session de travail, faisant retomber à zéro des mois d’efforts.
Pour résoudre ce problème, MemPalace utilise une architecture spatiale pour stocker la mémoire : les informations sont classées clairement dans des zones d’ailes représentant le personnel ou le projet, ainsi que dans une structure à différents niveaux comme des couloirs, des pièces et des tiroirs, afin de conserver le texte original du dialogue pour des recherches sémantiques ultérieures.
L’équipe de développement affirme que MemPalace obtient 100 % dans le critère d’évaluation de la mémoire à long terme LongMemEval, et qu’il atteint 96,6 % de précision sans appeler n’importe quelle API externe. De plus, il peut s’exécuter entièrement localement, sans nécessiter d’abonnement à un service cloud, et est accompagné d’un système de dialecte AAAK présenté comme permettant une compression sans perte jusqu’à 30 fois.
Source de l’image : GitHub La star hollywoodienne Milla Jovovich crée un palais de mémoire IA, suscitant l’attention du public
Collègues et communauté remettent en question la qualité, des tests et de la promotion comportent des défauts
Cependant, le score parfait de MemPalace sur LongMemEval a rapidement suscité des doutes de la part des collègues.
PenfieldLabs, qui développe aussi des systèmes de mémoire IA, a indiqué que la revendication de MemPalace selon laquelle il obtient un score parfait sur le jeu de données LoCoMo est mathématiquement impossible, car les réponses standard de ce jeu de données contiennent elles-mêmes 99 erreurs.
L’analyse de PenfieldLabs a montré que le score de 100 % de MemPalace provient du fait que le nombre de récupérations a été fixé à 50 fois, alors que le nombre maximum d’étapes de dialogue dans les données de test n’est que de 32 fois. Cela signifie que le système contourne directement l’étape de récupération et livre toutes les données au modèle IA pour lecture.
Concernant le score de 100 % de LongMemEval, l’équipe de développement a été repérée comme ayant ciblé 3 problèmes spécifiques ayant conduit à une erreur de consolidation lors du développement ; elle a rédigé des codes de réparation dédiés, ce qui soulève des soupçons de triche sur l’ensemble de test.

Source de l’image : Reddit PenfieldLabs souligne que la revendication de MemPalace selon laquelle il obtient un score parfait sur le jeu de données LoCoMo est mathématiquement impossible
Tests de la part des utilisateurs GitHub : des facteurs trompeurs dans le benchmark
L’utilisateur GitHub hugooconnor, après l’avoir testé en conditions réelles, a fait le commentaire suivant : lorsque MemPalace revendique une précision de récupération allant jusqu’à 96,6 %, en réalité, il n’utilise absolument pas l’architecture du palais de mémoire mise en avant par MemPalace. hugooconnor affirme que leurs tests se contentent d’appeler la fonctionnalité par défaut du système de base de données sous-jacent ChromaDB, sans aucune logique de classification impliquant les zones d’ailes, les pièces ou les tiroirs mis en avant par le projet.
Après avoir testé, hugooconnor a constaté que lorsque le système active réellement cette logique de classification exclusive au palais de mémoire, les performances de récupération se dégradent. Par exemple, en mode pièces, la précision chute à 89,4 % ; et une fois la technologie de compression AAAK activée, la précision tombe encore à 84,2 % ; dans les deux cas, les résultats sont inférieurs aux performances du dépôt de données par défaut.
hugooconnor a aussi critiqué la méthode de test : l’environnement de test de MemPalace réduit volontairement la portée de récupération pour chaque question à environ 50 étapes de dialogue. Chercher des réponses dans une base de petits échantillons rend l’exercice trop simple.
Si la portée est étendue à plus de 19 000 étapes de dialogue dans des situations réelles, la précision de la recherche par mots-clés classique chuterait à 30 %, montrant que la méthode de test actuelle de MemPalace masque le vrai problème de difficulté de recherche.
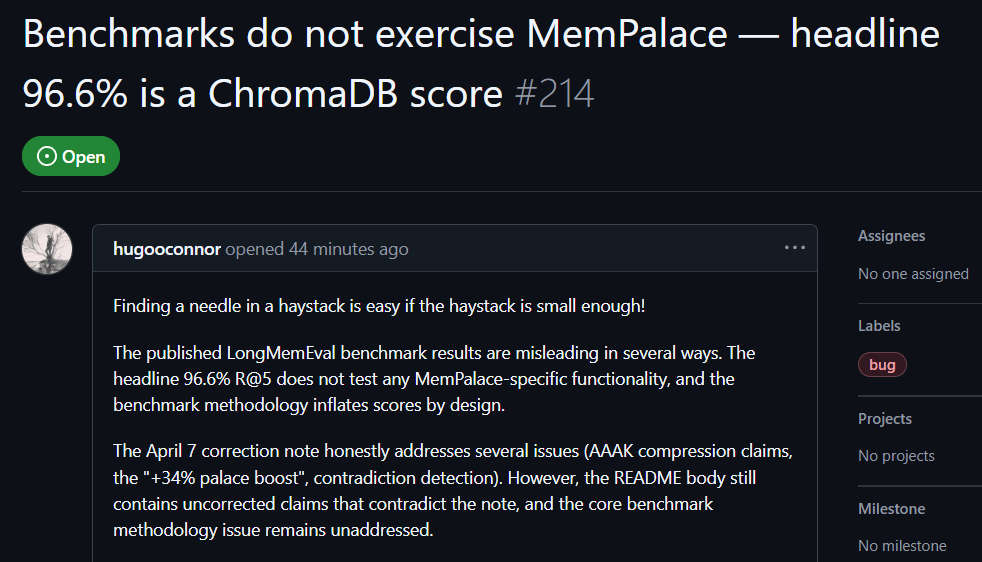
Source de l’image : GitHub Tests réels des utilisateurs GitHub, la partie benchmark de MemPalace comporte des éléments trompeurs
En parallèle, bien que l’équipe de développement ait déjà publié une déclaration de correction, reconnaissant que la technologie AAAK est effectivement une compression avec perte et s’engageant à ajuster la documentation et la conception du système selon les critiques sévères de la communauté, la documentation principale du projet conserve néanmoins plusieurs affirmations exagérées non corrigées, notamment la revendication de 30 fois de compression sans perte et une hausse de 34 % de la récupération, et les comparatifs sous forme de graphiques avec d’autres concurrents ne fournissent également aucune source.
Le code source de MemPalace fait face à plusieurs bugs
À mesure que de plus en plus de développeurs téléchargent et testent, de nombreux rapports de bugs concernant le code source de MemPalace apparaissent sur la plateforme GitHub.
L’utilisateur cktang88 a listé plusieurs défauts graves, notamment : les commandes de compression ne fonctionnent pas et provoquent le crash du système, une erreur dans la logique de calcul du nombre de mots pour les résumés, une statistique inexacte pour l’extraction des données des pièces, et aussi le fait que le serveur charge toutes les données d’interprétation en mémoire à chaque appel, entraînant un problème important de consommation de ressources.
Parmi les autres problèmes signalés, il y a aussi le fait que le système écrit en dur le nom des membres de la famille des développeurs dans le fichier de configuration par défaut, ainsi qu’une limite d’affichage forcée à 10k entrées de données lors de la consultation de l’état.
Face à ces problèmes, la communauté open source a commencé à corriger activement. L’utilisateur adv3nt3 a soumis plusieurs requêtes deréparation, notamment la correction des statistiques d’extraction, le retrait des noms de membres de la famille par défaut, et le report du moment d’initialisation de la création de la base de connaissances. L’équipe de développement a également reconnu ces erreurs par la suite et résout progressivement les problèmes de code via la collaboration communautaire.
Vibe Coding de Milla Jovovich, c’est cool ; la manière marketing, elle, ne l’est pas
Concernant ce projet MemPalace, un utilisateur de Hacker News, darkhanakh, a tiré la conclusion suivante : MemPalace donne une impression de déjà-vu d’OpenClaw, c’est-à-dire qu’on manipule artificiellement les résultats d’un benchmark pour qu’ils paraissent parfaitement irréprochables, puis qu’on le conditionne et le mette en avant comme une sorte de percée majeure pour le marketing.
Il pense que la technologie sous-jacente de MemPalace pourrait effectivement être intéressante, mais dans un contexte où la méthode de test comporte de tels défauts, et qu’en plus on fasse la promotion avec « le score le plus élevé jamais rendu public », ce n’est vraiment pas approprié. « Mais bon, le fait que Milla Jovovich joue à Vibe Coding, je trouve que ça reste quand même plutôt cool. »
Lecture complémentaire :
AI écrit du code avec des ratés ! L’app « Chasseurs anti-gaspillage » de produits à date limite en supermarché révèle des problèmes de cybersécurité, avec le GPS à nu à la maison