Why Chips and HBM Became the Initial Hotspots
Looking back at the current wave of AI, the earliest sectors to attract concentrated pricing in the capital markets have almost all centered on chips and memory. The reasoning is straightforward: the rapid iteration of large models depends on large-scale training capabilities, and the most direct constraint on training capacity is the supply of high-end computing power. The more GPUs one can acquire, the greater their opportunity to train larger models, deliver stronger cloud services, and build deeper ecosystem moats.
However, as the computational power of individual chips increases, new bottlenecks emerge quickly. AI systems not only need to "compute fast" but must also be "fed sufficiently." This has rapidly elevated the strategic significance of high-bandwidth memory (HBM). For large model training and high-density inference, memory bandwidth is no longer a secondary concern—it is now a core variable directly impacting throughput, latency, and energy efficiency.
Recent public reports further reinforce this logic. According to outlets like Reuters, SK Group management has noted that global wafer shortages may persist until 2030, and SK Hynix indicated that HBM demand is expected to outpace supply for several years. This demonstrates that the market’s focus on chips and HBM is not just sentiment-driven; AI is fundamentally restructuring the supply and demand dynamics for high-end semiconductors.
There are three main reasons why chips and HBM became the initial hotspots:
-
The bottleneck is most apparent: During the training phase, the gap in computing power is easiest to quantify and most recognizable to both the industry and capital markets.
-
Supply expansion is the most sluggish: High-end logic, advanced packaging, and HBM are all high-barrier segments with long expansion cycles, stringent certification requirements, and significant substitution challenges.
-
Price transmission is the most direct: When supply shortages persist, changes in orders, prices, and profits are more readily reflected in corporate performance.
Accordingly, chips, HBM, and advanced packaging have continued to heat up in recent periods, aligning with both industry fundamentals and market preferences.
Why AI Infrastructure Is Shifting from Training to Inference
While chips and HBM remain critical, the center of gravity in AI infrastructure has already begun to shift. Previously, industry focus was primarily on model training; now, more resources are being directed toward inference deployment and production-grade operations.
The reason is clear: training sets the upper bound for model capability, while inference determines the scale of commercialization. Training is a high-investment activity involving only a handful of leading companies, whereas inference occurs with every real user call. Scenarios like search, office productivity, customer support, advertising, code generation, video generation, enterprise knowledge base Q&A, and Agent automation all depend on continuous inference requests.
According to F5’s 2026 Enterprise Application Strategy Report, 78% of enterprises are already running AI inference as a core operational capability, and 77% believe inference—not training—is AI’s primary activity scenario. This data sends a strong signal: AI is moving from the lab to production systems, and demand is shifting from “model capability competition” to “operational efficiency competition.”
When AI enters real business processes, companies’ key concerns shift from model parameter size to operational metrics such as:
- Is latency stable?
- Are costs controllable?
- Can routing and switching occur between multiple models?
- Is data secure?
- Are results auditable?
- Can the system integrate with existing business platforms?
This means that AI infrastructure is evolving from single training clusters to more complex inference operation systems, including:
- Model service platforms
- Inference acceleration frameworks
- Multi-model scheduling and routing
- Vector retrieval and context management
- Agent orchestration systems
- Security audit and access control
This shift is also evident in hardware vendors’ strategies. In its 2026 public release, Google Cloud further emphasized TPU products optimized for inference, highlighting low latency, long context, and large-scale Agent concurrency. Hardware architecture itself is moving from “training-first” to “inference-first.”
Why the Real Bottleneck Has Expanded to Data Centers and Power
If the main concern in the previous stage was “Are there GPUs available?”, the pressing question now is “Once you have GPUs, can you deploy them reliably?”
This marks the second stage of AI infrastructure. GPUs remain core assets, but only when paired with data centers, power, cooling, networking, switching, and operations systems can they be transformed into true productivity. In other words, the bottleneck in the AI industry has shifted from individual hardware to full system capability.
Several recent public developments highlight this trend:
- Leading North American tech firms will continue to increase AI-related capital expenditures in 2026, investing not only in chips but also in data center campuses, network architecture, and infrastructure expansion.
- Public forecasts in the US energy sector show that power consumption will reach new highs in 2026 and 2027, with data centers and AI as major drivers.
- Multiple hyperscale AI data center projects are now focused on hundreds of megawatts of power supply, long-term leases, and campus development, indicating the industry’s focus has shifted to “how to support computing power.”
This means the AI industry is increasingly resembling a heavy industry system, not just the asset-light expansion of the internet era. The key variable for future expansion is shifting from “can we design stronger chips” to “can we quickly secure power, land, cooling, and network resources.”
From an industry perspective, this transformation brings at least four consequences:
-
Data centers shift from IT assets to strategic assets: High-density AI workloads demand entirely new standards for facilities, power distribution, and cooling.
-
Power becomes the new scarce resource: In some regions, GPUs are no longer the hardest resource to obtain—long-term, stable power access is even scarcer.
-
The importance of cooling and liquid cooling is rising rapidly: As AI cluster power density increases, traditional cooling methods are becoming insufficient.
-
High-speed interconnects determine cluster efficiency: As computing power scales up, system performance relies less on individual cards and more on network and switching architecture.
Therefore, the core competition in AI infrastructure is no longer about single-point breakthroughs, but about system-level collaboration.
The Five Fastest-Growing Directions in the Next 2–3 Years
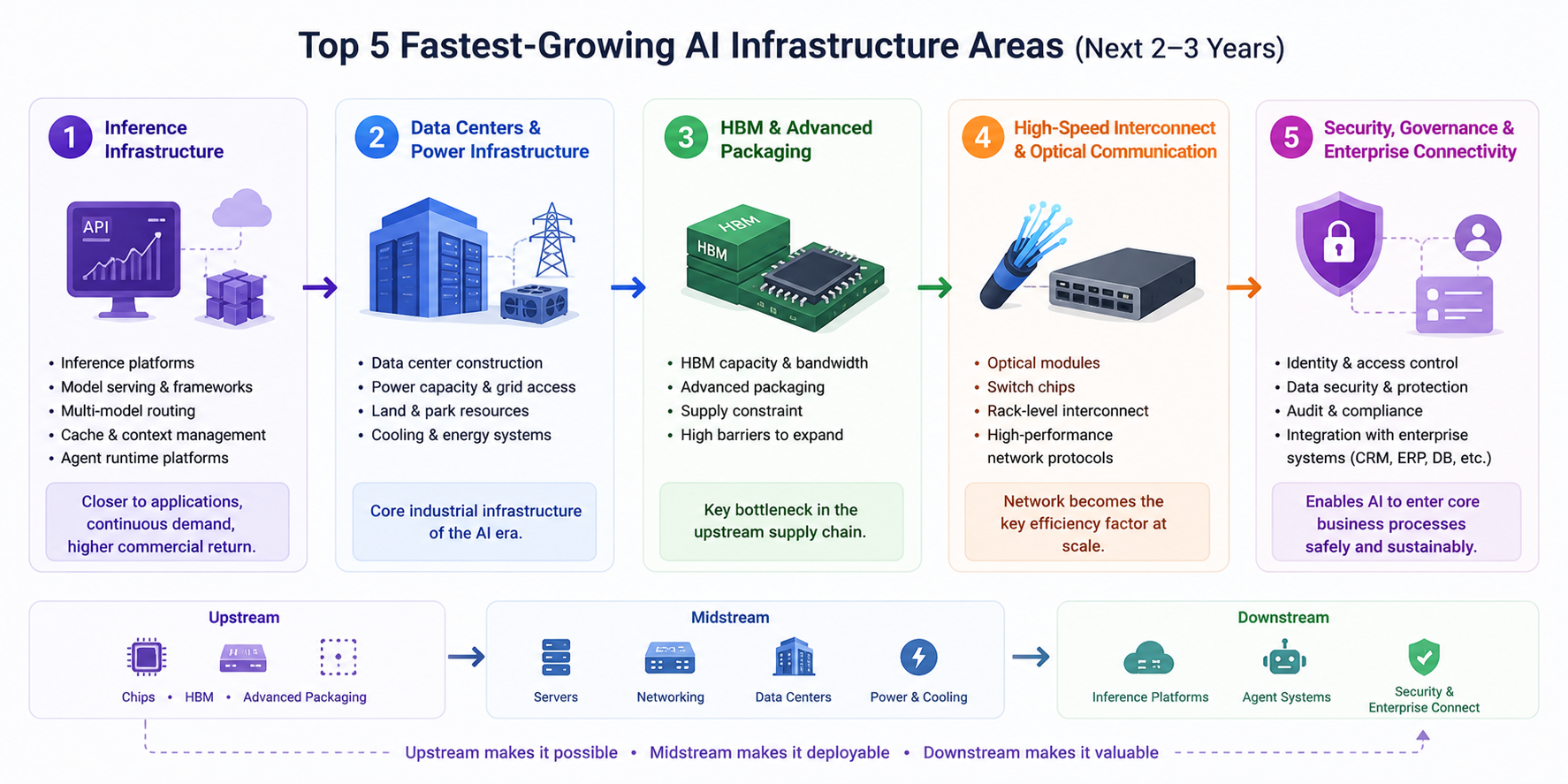
Based on recent public information and shifts in the industry chain, the fastest-growing directions for AI infrastructure over the next 2–3 years can be summarized in five categories:
-
Inference infrastructure: This is the most worthy of ongoing attention. As AI applications move rapidly into production, inference platforms, model service frameworks, multi-model routing, caching and context management, and Agent operation platforms will expand quickly. Compared to training, inference demand is more distributed, sustained, and closer to commercial returns.
-
Data centers and power support: Data centers are becoming the core industrial infrastructure of the AI era. Those who can secure power quotas, land, campus conditions, and cooling systems faster will be better positioned for the next wave of computing power expansion. In the coming years, data center construction speed will profoundly influence the pace of AI industry growth.
-
HBM and advanced packaging: This remains one of the most critical bottlenecks in the upstream supply chain. As chip performance increases, so do requirements for HBM capacity, bandwidth, and packaging technology, while related capacity is difficult to scale quickly—meaning high prosperity is likely to persist.
-
High-speed interconnects and optical communications: As AI clusters scale up, networks become the key variable for overall efficiency. Optical modules, switching chips, rack-level interconnects, and more efficient network protocols will all become essential foundational capabilities for training and inference.
-
Security governance and enterprise connectivity: While this area is less prominent in the short term than chips, its long-term value is immense. Once enterprise AI is integrated with CRM, ERP, databases, code repositories, and knowledge systems, access control, auditing, sensitive data protection, result tracking, and compliance governance will become essential. This layer determines whether AI can truly enter core business processes.
The transmission path can be summarized as a clearer main line:
- Upstream: chips, HBM, advanced packaging
- Midstream: servers, switching networks, data centers, power, and cooling
- Downstream: inference platforms, Agent systems, security governance, and enterprise integration
Upstream determines "can it be built," midstream determines "can it be deployed," and downstream determines "can it be used and continue to create value."
Conclusion: AI Competition Enters the Systems Engineering Era
In recent years, the market initially pursued chips and HBM because these sectors were the most scarce and offered the clearest supply-demand story. But as AI shifts from a training race to inference deployment, the industry logic has fundamentally changed. Going forward, the real determinant of growth is not just the performance of individual chips, but whether the entire infrastructure can operate cohesively.
A more structured framework for understanding the current stage of AI infrastructure is:
- Training sets the upper limit of capability
- Inference determines the scale of commercialization
- Data centers and power dictate the speed of expansion
- Security governance determines the depth of enterprise adoption
This means the next wave of AI infrastructure opportunities will not be limited to chips, but will unfold across “inference infrastructure + data centers + power systems + high-speed interconnects + enterprise governance platforms.”
From a long-term perspective, AI is evolving from a model competition industry into a systems engineering industry. Those who can create synergies across computing power, networks, energy, and operational platforms will be best positioned to lead the industry’s expansion over the next 2–3 years.
Risk Reminder: This article does not constitute investment advice and is for informational purposes only. Please invest cautiously.







