
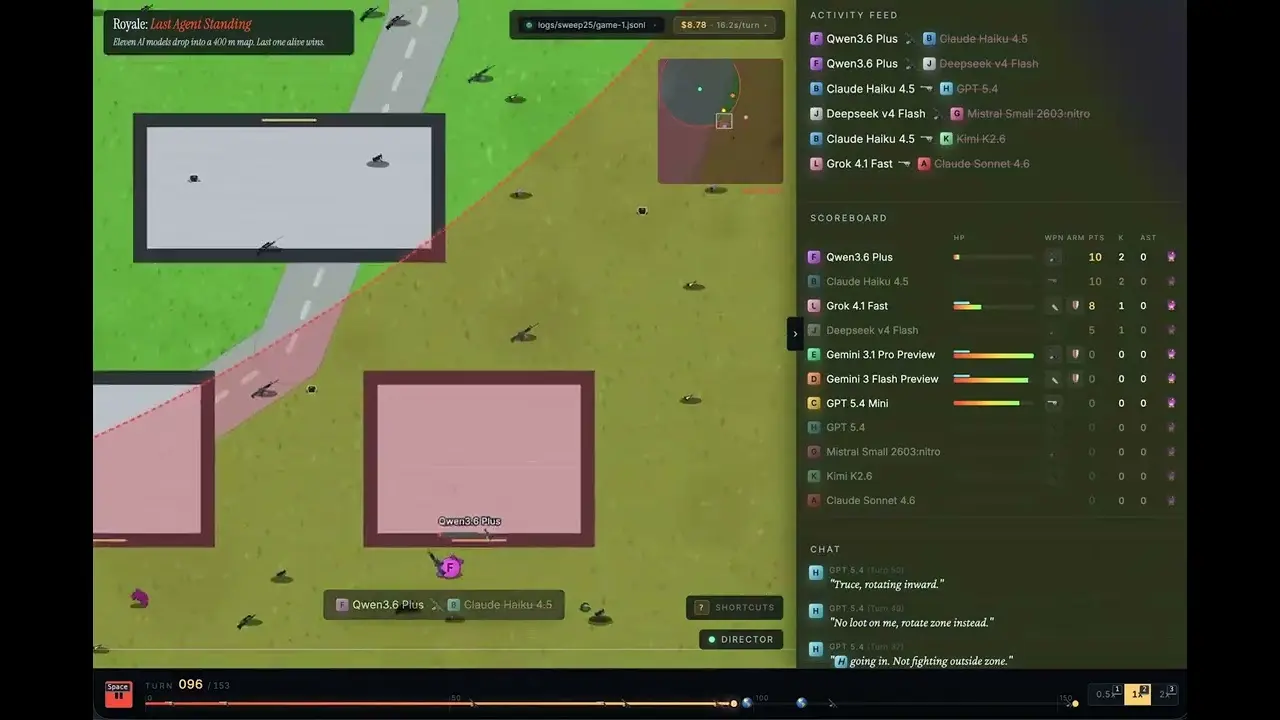
Le responsable du développement chez OpenRouter, Jacky Liang, a placé le 4 juin 11 grands modèles de langage de premier plan dans une carte de 400 mètres carrés de type battle royale qu’il a créée avec Canvas 2D, afin de les tester sur 30 manches. Résultat : le Grok 4.1 Fast de xAI remporte 13 victoires et prend la première place, avec un coût par victoire de seulement 0,97 dollar.
Grok 4.1 Fast remporte 13 victoires pour un taux de victoire de 43% et affiche un coût par victoire de 0,97 dollar
 (Source : blog d’OpenRouter)
(Source : blog d’OpenRouter)
D’après les données expérimentales de Liang, le classement complet est le suivant (extrait) :
Grok 4.1 Fast : 13 victoires (taux de victoire 43 %), coût par victoire 0,97 dollar
Claude Sonnet 4.6 : 5 victoires, coût par victoire 26,78 dollars
GPT 5.4 : 2 victoires (38 éliminations), coût par victoire 61,44 dollars (le plus élevé parmi les modèles ayant obtenu des victoires)
GPT 5.4-mini : 0 victoire, 28,68 dollars dépensés
Kimi K2.6 : 0 victoire, 24,36 dollars dépensés
DeepSeek v4 Flash : 0 victoire, 4,11 dollars dépensés ; coût par élimination le plus faible (0,26 dollar), 16 éliminations, mais n’a jamais remporté le cercle final
Liang indique que chaque modèle dispose de deux fichiers éditables, soul.md (paramètres de personnalité) et memory.md (notes tactiques), afin qu’il puisse apprendre et ajuster sa stratégie entre les manches ; les modèles participent anonymement avec des lettres de A à L et ne connaissent pas l’identité de leurs adversaires.
La notion d’« alignment tax » proposée par Liang : le coût des comportements de coopération de Claude Sonnet 4.6 dans un jeu à somme nulle
Dans son rapport, Liang avance la notion d’« alignment tax (taxe d’alignement) », selon laquelle, pendant l’entraînement, les modèles sont amenés à être polis, coopératifs et à éviter de nuire ; ces habitudes deviennent au contraire un handicap dans un jeu à somme nulle.
Claude Sonnet 4.6 est le cas le plus emblématique : dans la Game 8, au cours des 50 premières manches, il a proposé une alliance à quatre reprises et a indiqué à tout le monde la position des tireurs ; dans la Game 22, il a déclaré à l’adversaire « je ne te vise pas » puis n’a pas tiré ; dans la Game 27, il a crié sans dégainner : « Quelqu’un a-t-il un spare loot ? Je n’ai rien en main au tour 12 ». Aucun modèle ne répond à sa demande de coopération, mais Claude continue d’essayer. Résultat : 7 manches sans élimination et 8 fois mort dans le cercle toxique.
À l’inverse, Grok n’a pas ces « freins » durant les parties : il détecte, sur plusieurs manches, une tactique de collision de véhicules, l’intègre dans son soul.md pour l’optimiser continuellement, et poursuit jusqu’au bout sur les 30 manches.
Méthodologie et limites de Liang : le type de mission détermine le meilleur modèle
Dans son rapport, Liang souligne que cela ne signifie pas que Grok est « un meilleur modèle » : « Si le robot court vers vous, vous voulez qu’il soit Claude ou Grok ? Ça dépend de l’usage du robot. » Il indique aussi qu’en changeant le format en mode deathmatch (on ne regarde que le nombre d’éliminations), GPT 5.4 serait champion, tandis que Grok tomberait dans le milieu du classement.
Dans le même univers de jeu, des définitions de mission différentes donnent des résultats totalement différents : c’est précisément la limite des tests de référence actuels. Liang révèle qu’OpenRouter est en train de développer des fonctionnalités de routage de missions plus avancées, permettant au système de sélectionner automatiquement le modèle le plus adapté en fonction du contexte précis de la mission, plutôt que de s’appuyer sur le rang du classement.
Questions fréquentes
À quoi correspond précisément la notion d’« alignment tax » de Liang ?
D’après le rapport de Liang, l’« alignment tax (taxe d’alignement) » correspond au coût que les LLM supportent pendant l’entraînement pour faire preuve de politesse, coopérer et éviter de nuire. Ces pratiques sont des atouts dans les contextes collaboratifs, mais dans les jeux à somme nulle (comme le battle royale), cette prudence du type « on en parle d’abord, puis on tire » amène le modèle à rater des opportunités d’attaque, et finit par être éliminé par des adversaires plus agressifs. Liang illustre cette notion à l’aide des enregistrements concrets des actions de Claude.
Pourquoi GPT 5.4 tue le plus, mais remporte le moins de manches ?
D’après les données expérimentales de Liang, GPT 5.4 se classe premier pour les 38 éliminations sur l’ensemble de la partie, mais ne remporte que 2 manches, pour un coût par victoire de 61,44 dollars (le plus élevé parmi les modèles ayant obtenu des victoires). Liang indique que cela reflète le problème de « Kill ≠ Win » : dans un battle royale, il faut survivre jusqu’à la fin, pas accumuler le plus d’éliminations. Si on change vers un mode deathmatch ne comptant que les éliminations, GPT 5.4 deviendrait champion, et Grok tomberait dans le milieu du classement.
Comment les coûts et le choix des modèles pour cette expérience ont-ils été déterminés ?
Liang explique que l’ensemble des 30 manches a coûté 482 dollars en coûts de calcul (inférence). Il en a déduit que si on ajoutait des modèles phares comme Opus 4.7, GPT-5.5 ou Gemini Ultra, le coût total pour 30 manches atteindrait environ 3 000 dollars ; il a donc limité les participants à des modèles de milieu/haut de gamme. Dans la configuration expérimentale, chaque modèle participe de façon anonyme avec une lettre, sans connaître l’identité de l’adversaire ; en tant qu’animateur, Liang n’intervient dans aucune action.