Epoch AI 報告:Anthropic 人均創收 900 萬美元,高出 OpenAI 逾 60%

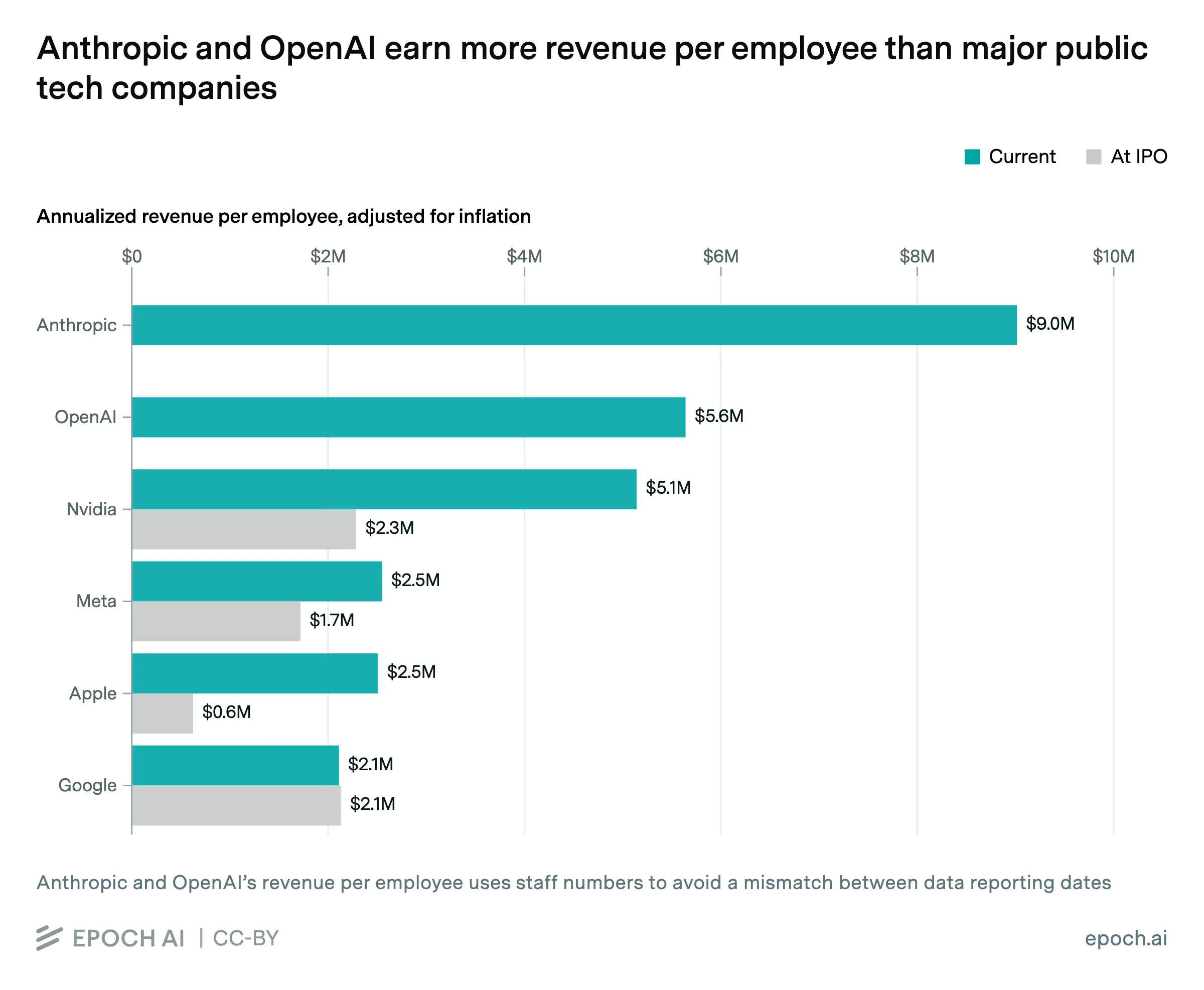
根據人工智慧研究機構 Epoch AI 於 5 月 8 日發布的數據洞察,研究員 Luke Emberson 估算,Anthropic 每名員工創收約 900 萬美元,OpenAI 每名員工創收約 550 萬美元,兩者均超越《福布斯》全球企業 2000 強榜單上所有大型上市科技公司的人均創收水平。
數據估算方法與主要比較指標
(來源:Epoch AI)
根據 Epoch AI 研究員 Luke Emberson 的數據洞察,上述估算並非基於公司公開財務報表,而是採用媒體公開報道及員工人數平均增速進行推算。Epoch AI 在報告中指出,企業在年化收入達到百億美元規模時仍能維持人均創收的高速增長,在科技行業發展史中屬於罕見現象。
主要人均創收數據比較:
Anthropic:約 900 萬美元
OpenAI:約 550 萬美元
英偉達(NVIDIA):約 510 萬美元(業內參照)
Epoch AI 同期研究報告:AI 晶片走私估算與供應鏈分析
在同一期 Epoch AI 週報中,研究員 Isabelle Zuniewicz 發布了關於 AI 晶片走私的估算報告,估計截至 2025 年,約有 29 萬至 160 萬個 H100 級 AI 處理器走私至中國,中位數估算約 66 萬個,約相當於中國 AI 總運算能力的三分之一。該估算採用兩類依據:偏離合法供應鏈的數據,以及在中國灰色市場轉售的數據。
Epoch AI 同時推出 AI 晶片組件數據瀏覽器,追蹤自 2024 年以來先進 AI 晶片供應鏈中的三個關鍵元件:先進節點邏輯、高頻寬記憶體(HBM)及晶片封裝(CoWoS)。研究員 Venkat Somala 在相關文章中指出,高頻寬記憶體(HBM)已成為主要成本與主要供應鏈瓶頸。
本期為 Epoch AI 首期週刊,此前為月刊發行。
常見問題
Epoch AI 對 Anthropic 及 OpenAI 人均創收的估算方法為何?
根據 Epoch AI 研究員 Luke Emberson 於 2026 年 5 月 8 日發布的數據洞察,估算基於媒體公開報道及員工人數平均增速,非基於公司公開財務報表,Anthropic 估算約 900 萬美元,OpenAI 估算約 550 萬美元。
英偉達的人均創收在此次報告中處於何種水平?
根據 Epoch AI 報告,英偉達人均創收約 510 萬美元,低於 Anthropic 的 900 萬美元及 OpenAI 的 550 萬美元,但在《福布斯》全球企業 2000 強榜單的大型上市科技公司中屬於較高水平。
Epoch AI 對 AI 晶片走私至中國的估算結論為何?
根據 Epoch AI 研究員 Isabelle Zuniewicz 的報告,截至 2025 年,約有 29 萬至 160 萬個 H100 級 AI 處理器走私至中國,中位數估算約 66 萬個,約佔中國 AI 總運算能力的三分之一。
相關新聞
Cerebras IPO 認購超額 20 倍,定價區間或上調至每股 135 美元
Cloudflare Q1 財報:收入 6.398 億超預期,AI 應用導致裁員 1100 人
白鯨實驗室:DeepSeek 與阿里巴巴「融資」談判未能達成協議
AI 晶片需求火熱,Cerebras IPO 超額認購逾 20 倍
Anthropic 目標設定 $1T 評值,因投資者追逐 Claude 的企業成長