Фьючерсы
Доступ к сотням фьючерсов
CFD
Золото
Одна платформа мировых активов
Опционы
Hot
Торги опционами Vanilla в европейском стиле
Единый счет
Увеличьте эффективность вашего капитала
Демо-торговля
Введение в торговлю фьючерсами
Подготовьтесь к торговле фьючерсами
Фьючерсные события
Получайте награды в событиях
Демо-торговля
Используйте виртуальные средства для торговли без риска
CFD
Деривативы CFD на акции США
Акции США
Доступ к реальным акциям США и ETF
Акции Гонконга
Торгуйте качественными акциями, котирующимися в Гонконге
Фьючерсы на акции
Высокое кредитное плечо, круглосуточная торговля
Токенизированные акции
Обеспечено реальными акциями
IPO Access
Откройте полный доступ к глобальным IPO акций
GUSD
Создать GUSD для получения доходности казначейских RWA
Мероприятия, связанные с акциями
Торгуйте популярными акциями и получайте щедрые эирдропы
Запуск
CandyDrop
Собирайте конфеты, чтобы заработать аирдропы
Launchpool
Быстрый стейкинг, заработайте потенциальные новые токены
HODLer Airdrop
Удерживайте GT и получайте огромные аирдропы бесплатно
IPO Access
Откройте полный доступ к глобальным IPO акций
Alpha Points
Торгуйте и получайте аирдропы
Фьючерсные баллы
Зарабатывайте баллы и получайте награды аирдропа
Инвестиции
Simple Earn
Зарабатывайте проценты с помощью неиспользуемых токенов
Автоинвест.
Автоинвестиции на регулярной основе.
Бивалютные инвестиции
Доход от волатильности рынка
Мягкий стейкинг
Получайте вознаграждения с помощью гибкого стейкинга
Криптозаймы
0 Fees
Заложите одну криптовалюту, чтобы занять другую
Центр кредитования
Единый центр кредитования
Рекламные акции
Промоакции
Участвуйте и получайте награды
Реферал
20 USDT
Приглашайте друзей за бонусы
Партнерская программа
Эксклюзивные комиссионные
Gate Booster
Растите влияние и получайте аирдроп
Анонсы
Обновления в реальном времени
Блог Gate
Статьи о криптоиндустрии
VIP-услуги
Огромные скидки на комиссии
Управление активами
Универсальное решение для управления активами
Институциональный
Крипто-решения для бизнеса
Разработчикам (API)
Подключение к экосистеме приложений Gate
Внебиржевые банковские переводы
Ввод и вывод фиатных денег
Брокерская программа
Щедрые механизмы скидок API
AI
Gate AI
Ваш универсальный AI-ассистент для любых задач
Gate AI Bot
Используйте Gate AI прямо в вашем социальном приложении
GateClaw
Gate Синий Лобстер — готов к использованию
Gate for AI Agent
AI-инфраструктура: Gate MCP, Skills и CLI
Gate Skills Hub
Более 10 тыс навыков
От офиса до трейдинга: единая база навыков для эффективного использования ИИ

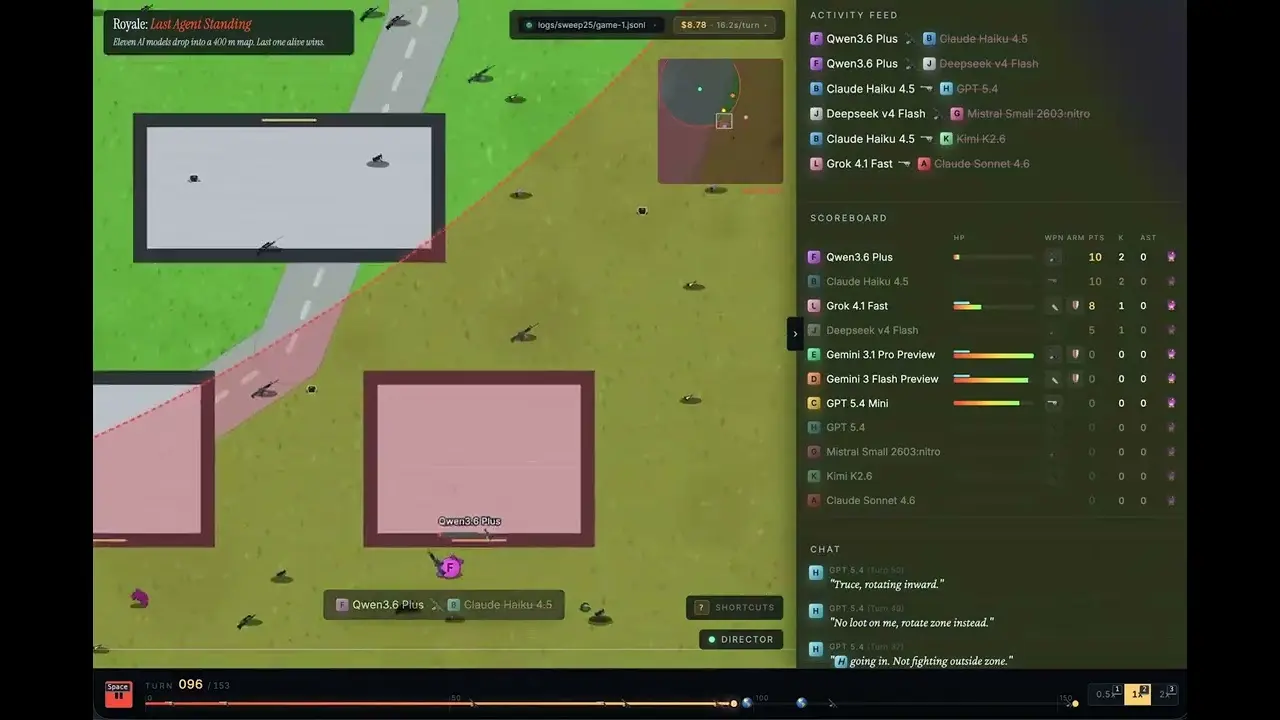 (Источник:блог OpenRouter)
(Источник:блог OpenRouter)