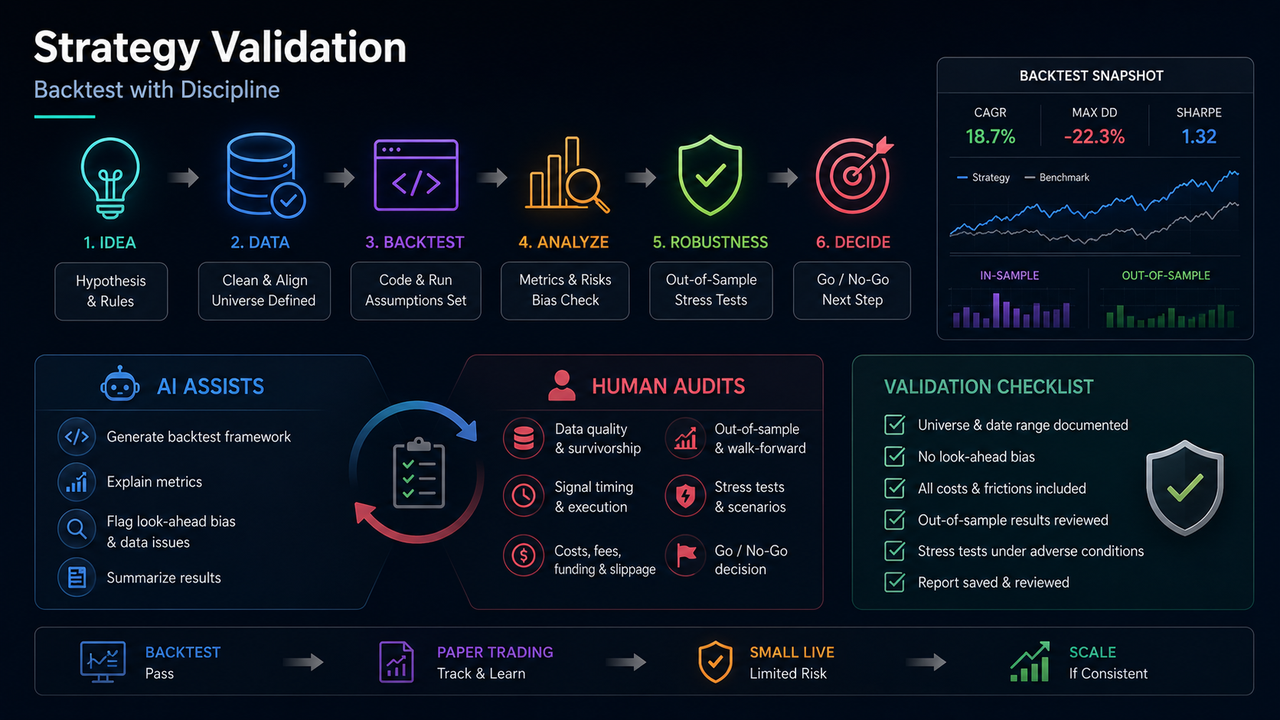
1. Starting Point: The Goal of Validation Is Not "Proving Profitability"
The previous two lessons addressed division of labor in the workflow and input structure. Lesson three moves to whether an idea demonstrates historical consistency. Many failures don't stem from fundamentally wrong directions, but from backtests being treated as conclusions without proper auditing: data includes delisted assets, signals use future information, costs are omitted, parameters are repeatedly tweaked on short samples. AI can speed up code writing and indicator interpretation but cannot make the final determination on whether a strategy is valid. The more reasonable goal of validation is: under clear assumptions, the strategy has not been statistically or cost-wise falsified—not proving inevitable profitability through smooth narrative.
2. Reasonable Division of Labor for AI in Backtesting
AI is suitable for assisting with:
-
Generating backtest framework code
-
Explaining the meaning of Sharpe ratio, maximum drawdown, win rate
-
Listing potential points of look-ahead bias
-
Organizing results tables into text summaries
Tasks that must be completed or reviewed independently by humans include:
-
Whether the universe contains survivors
-
Whether prices existed before listing
-
Whether fees, slippage, and funding rates are included
-
Whether out-of-sample or walk-forward tests are executed
-
Whether paper vs. live discrepancies are considered
Code running only indicates engineering steps are complete; it does not mean the strategy has passed validation.
3. Data Cleansing: The Most Fragile Step in Crypto Backtesting
If a backtest uses only tokens still active today, results tend to be systematically optimistic. Periods before token listing should not be assumed tradable. Prices, volumes, and funding rates vary across exchanges; backtests should fix the exchange or specify synthesis rules. Forks, contract migrations, and token renaming cause price sequence breaks and require manual mapping or exclusion. Using a single stablecoin for pricing during depeg phases may distort return and risk metrics; major depeg windows should be separately marked or explained. AI should be required to list data sources, time ranges, and universe definitions in documentation and check each item against raw data—more important than merely chasing backtest curves.
4. Look-Ahead Bias: Time Alignment Between Signals and Execution
Common look-ahead biases include:
-
Using full-sample statistics for normalization but backtesting on the full sample
-
Generating signals at day's close but executing at day's open
-
Using addresses labeled as "smart money" only after the fact
-
Using revised macro data as if it were historical release values
Discipline should specify: signals generated at t must execute at t+1 or later depending on strategy type; if macro data can't be obtained as originally released, related conclusions should be downgraded. AI can be required to annotate data availability timing for each feature in code comments; humans should spot-check key features to ensure they precede execution by at least one day.
5. Costs and Friction: Backtests Without Fees Are Invalid by Default
Crypto strategies should at minimum include trading fees, slippage, perpetual funding rates (if positions cross settlement points), borrowing rates (if leverage is used), and withdrawal/cross-chain costs if necessary. Baseline and pessimistic fee scenarios (e.g., doubling fees) can be used for stress testing. If expected returns deteriorate sharply or turn negative under pessimistic scenarios, the strategy is highly cost-sensitive and shouldn't be judged solely by in-sample curves. AI often defaults to zero fees or a single basis point; humans must write fee tables into backtest assumptions and reports.
6. Overfitting and Out-of-Sample: More Parameters Require Greater Narrative Caution
Symptoms include:
-
Displaying only the best combination after many indicator sets
-
Tuning parameters only on short bull market samples
-
Highly specific rules with no mechanism explanation
Countermeasures include:
-
Reserving out-of-sample intervals that aren't used for parameter tuning
-
Applying rolling-window walk-forward testing
-
Simplifying rules as much as possible within explainable premises
Reports should present both in-sample and out-of-sample key metrics; if out-of-sample performance is significantly weaker than in-sample, overfitting risk should be flagged and live scaling paused. AI should not repeatedly optimize parameters unsupervised until the curve looks good—that amounts to automated overfitting.
7. From Backtest to Live Trading: Gradual Advancement Rather Than One-Step Launch
A three-level ladder is recommended. Level one: backtest passes with documented universe, fees, and out-of-sample results. Level two: paper or simulated trading records signal/execution price discrepancies and observes real-world slippage. Level three: small-size live trading with limits and stop-losses, continually comparing paper and live results. Advancement at each level is decided by humans—not models recommending heavy positions. AI can generate checklists for each level but cannot substitute for advancement decisions.
8. Minimum Fields in a Backtest Report
Even without complex systems, a report should include:
-
One-sentence strategy description
-
Data interval and asset scope
-
Fee assumption table
-
In-sample and out-of-sample returns, maximum drawdown, number of trades
-
Maximum consecutive loss
-
List of unresolved issues
-
Conclusion to continue validation, pause, or abandon
Avoid statements like "cautiously optimistic" that don't guide action. Backtests and reviews share the same discipline: executable, auditable, repeatable.
9. Lesson Summary
This lesson centers on whether ideas have been tested. AI is suitable for helping write backtest code, explaining indicators, flagging look-ahead bias and missing fees; it's not suitable for replacing human confirmation of survivor bias in data, signal/execution alignment, out-of-sample performance, or margin under pessimistic costs. Code running and good-looking in-sample curves only mean engineering steps are done—not that live scaling is justified. A safer path is documenting backtests then tracking on paper before small-scale trial-and-error—each step upward decided by humans. The next lesson will cover macro and major on-chain events: periods with the most information but also most likely to mistake summaries for conclusions, requiring clear boundaries on what AI can help prepare and what it cannot substitute for verification.